Suurten lukujen laki vaalistatistiikalle
| Tämä sivu on tutkimus.
Sivutunniste: Op_fi2800 |
|---|
| Moderaattori:smxb (katso kaikki)
Sivun edistymistä ei ole arvioitu. Arvostuksen määrää ei ole arvioitu (ks. peer review). |
| Lisää dataa
|
Sisällysluettelo
Gaussinen jakauma raja-arvona
Tässä kappaleessa perustellaan gaussisen jakautuman käyttöä vaalidatan aktiivisuus- ja kannatausprosenttijakautumien sovituksessa.
Useista aineistoista voidaan havaita että puoluekohtaisten kannatusprosenttien jakautumat kuten maakohtaiset äänestysaktiivisuusjakautumat ovat usein likipitäen normaalijakatuneita. Poikkeamille löytyy syitä, jotka vaihtelevat äänestäjien määrästä tahalliseen huijaukseen. Näiden vaikutusten erottaminen toisistaan on tärkeää oikean tulkinnan varmistamiseksi. Tämän vuoksi tutkimme alla millaisia jakaumia on odotettavissa ns. rehellisissä vaaleissa ja kuinka lähellä ne ovat normaalijakaumaa.
Jos äänestäjät olisivat täysin riippumattomia toisistaan, rehellisissä vaaleissa kokonaisaktiivisuus noudattaisi binomijakaumaa ja puolueiden kannatusjakauma noudattaa M-komponenttista multinomijakaumaa. Näiden jatkuvat vastineet ovat gaussisia normaalijakaumia (riippumattomuus implikoi korreloitumattomuutta). Todellisessa elämässä äänestäjien välillä on kuitenkin riippuvuuksia kuten mm. se että äänestäjät saattavat kuulua samaan puolueeseen tai esim. elää samalla maantieteellisellä alueella. Myös vaalivilppi kuten pakottaminen tai uurnien manipulointi voi indusoida korrelaatiota äänestystuloksiin. Korrelaatiolla ei kuitenkaan ole merkitystä, jos ne ovat ns. heikkoja ja äänestäjiä on riittävän suuri määrä. Heikko korrelaatio tarkoittaa sitä että äänestäjät eivät voi vuorovaikuttaa toistensa kanssa mielivaltaisen pitkän 'etäisyyden' yli (etäisyys voi olla konkreettinen (esim. maantieteellinen) tai abstrakti (esim. tuloluokka). Heikot korrelaatiot tyypillisesti vaimenevat nopeammin kuin potenssilakimuotoisena etäisyyden funktiona.
Mille tahansa satunnaismuuttujan, jolle on tehty affiininen muunnos niin että sen keskiarvo on saatettu nollaan ja varianssi ykköseksi [1] , jakauman karakteristiselle funktiolle pätee seuraava Taylor-laajennos pienillä Y:n arvoilla:
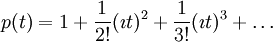 ,
,
missä 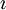 tarkoittaa imaginaariyksikköä. N:n samasta jakaumasta generoidun satunnaismuuttujan summan
tarkoittaa imaginaariyksikköä. N:n samasta jakaumasta generoidun satunnaismuuttujan summan
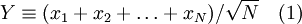
karakteristinen funktio puolestaan toteuttaa
![p_N\left( \frac{t}{\sqrt{N}} \right) = \left[ p\left( \frac{t}{\sqrt{N}} \right) \right]^N \approx \left[ 1 + \frac{1}{N} \left(-\frac{t^2}{2} - \frac{\imath t^3}{6 \sqrt{N}} + \ldots \right) \right]^N \to e^{-t^2/2}\, \left( 1 - \frac{\imath t^3}{6 \sqrt{N}} + \ldots \right)\, ,\ \ N \to \infty\ ,\ \ \ (2)](/fi-opwiki/images/math/2/2/d/22ddf702154268b0354f138892c5aefa.png)
missä suluissa olevat termit ovat äärelliselle summalle päteviä lisätermejä, jotka tekevät jakautumasta mahdollisesti epäsymmetrisen ja ei-gaussisen. Suorittamalla käänteis-Fourier -muunnoksen ja ottamalla palauttamalla ykkösestä poikkeavan varianssin 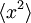 saamme jakauman
saamme jakauman
![P_N(Y) = \frac{1}{ \pi \langle x^2 \rangle }\, \exp\left( -\frac{Y^2}{2 \langle x^2 \rangle} + \frac{1}{\sqrt{N}} [\ldots] \right)\ ,](/fi-opwiki/images/math/e/0/d/e0d9c3e786baa6eb97fef9e1ea92ba23.png)
Hakasuluissa oleva lauseke riippuu jakatuman 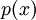 korkeammista kuin toisesta momentista. Se on lisäksi epäuniversaali siinä mielessä että kertoimet riippuvat satunnaisprosessin yksityiskohdista [2]. Jakautuman kertoimia voidaan käyttää sovitusparametreinä, joita voidaan arvioida erilaisilla tekniikoilla ml. Bayes-inferenssi, jota sovelletaan arvioinnin pääsivulla kappaleessa Hierarkkinen Bayes-malli.
korkeammista kuin toisesta momentista. Se on lisäksi epäuniversaali siinä mielessä että kertoimet riippuvat satunnaisprosessin yksityiskohdista [2]. Jakautuman kertoimia voidaan käyttää sovitusparametreinä, joita voidaan arvioida erilaisilla tekniikoilla ml. Bayes-inferenssi, jota sovelletaan arvioinnin pääsivulla kappaleessa Hierarkkinen Bayes-malli.
Yllä olevat kaavat pätisivät eksaktisti, mikäli oletamme että satunnaismuuttujat, jotka esiintyvät summassa (1) kuvaavat riippumattomia äänestäjiä ja ovat identtisesti jakautuneita. Kaavat pätevät asymptoottisesti myös ei-identtisille jakaumille [3] ja vaikka äänestäjien päätökset riippuisivatkin toisistaan tietyin edellytyksin. Tarkastellaan ensin kokonaisäänestysaktiivisuutta ja jaetaan summamuuttuja osasummiin
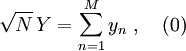
jossa osasummassa
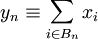
on 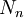 alkiota, joista jokainen kuuluu joukkoon
alkiota, joista jokainen kuuluu joukkoon 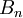 . Joukot oletetaan toisensa poissulkeviksi. Mikäli osasummien lukumäärä
. Joukot oletetaan toisensa poissulkeviksi. Mikäli osasummien lukumäärä 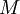 on riittävän suuri, voidaan tarkastella kokonaissummaan liittyvää normeerattua muuttujaa
on riittävän suuri, voidaan tarkastella kokonaissummaan liittyvää normeerattua muuttujaa
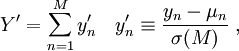
missä siis
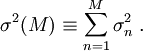
Yksittäisen (alijono)muuttujan 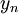 varianssi on siis
varianssi on siis 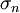 ja keskiarvo
ja keskiarvo 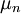 . Jos
. Jos
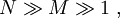
kaavassa (2) esitetty eksponentiaalinen muoto pätee Lyapunovin teoreeman perusteella kuten alla osoitetaan. Karakteristinen funktio summamuuttujan 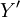 jakaumalle:
jakaumalle:
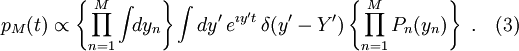
Tulon ositus antaa
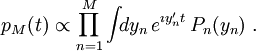
Laajentaen jokaisen tulon jäsenen pienen argumentin rajalla saamme
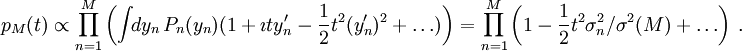
Eksponentioimalla saadaan
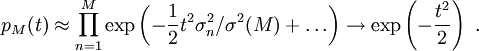
Toisin sanoen, vaikka muuttujat 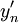 eivät olisi identtisesti jakautuneita, pätee kaava (2) erittäin tarkasti pienille poikkeamille keskiarvon ympäristössä myös kun on äärellinen.
eivät olisi identtisesti jakautuneita, pätee kaava (2) erittäin tarkasti pienille poikkeamille keskiarvon ympäristössä myös kun on äärellinen.
Kaavassa (3) on oletettu todennäköisyysjakauman 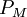 faktoroituvan täydellisesti:
faktoroituvan täydellisesti:
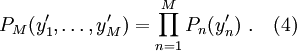
Tämä oletus on liian vahva käytäntöön sovellettuna, ja se voidaan korvata heikommalla oletuksella (vrt. ns. klusterihajotelma kenttäteoriassa). Toisin sanoen, oletus (4) voidaan relaksoida sallimalla osasummamuuttujien heikot korrelaatiot, siten että
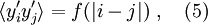
missä odotusarvo on laskettu alkuperäisen mikroskooppisen (mahdollisesti korreloituneen) äänestäjäjakauman yli:
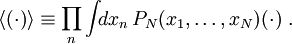
Edelleen kaavassa (5) korrelaatiofunktio 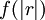 heikkenee riittävän nopeasti 'etäisyyden'
heikkenee riittävän nopeasti 'etäisyyden' 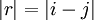 funktiona. Tällöin lisäämällä osasummamuuttujien summattavien määrää voidaan käytännön laskutoimituksia suorittaa käyttäen approksimaatiota (4) kokonaistodennäköisyysjakaumalle, vaikka se ei eksaktisti pätisikään. Etäisyysparametrina voidaan käyttää esim. maantieteellistä etäisyyttä. Jakaumaa karakterisoivia parametrejä voi olla useita muitakin mutta vaalidata ilmentää eksplisiittisesti ainoastaan vaalipiirien paikkatietoja.
funktiona. Tällöin lisäämällä osasummamuuttujien summattavien määrää voidaan käytännön laskutoimituksia suorittaa käyttäen approksimaatiota (4) kokonaistodennäköisyysjakaumalle, vaikka se ei eksaktisti pätisikään. Etäisyysparametrina voidaan käyttää esim. maantieteellistä etäisyyttä. Jakaumaa karakterisoivia parametrejä voi olla useita muitakin mutta vaalidata ilmentää eksplisiittisesti ainoastaan vaalipiirien paikkatietoja.
Yllä mainitut seikat pätevät erityisen hyvin äänestysaktiivisuus-muuttujalle, joka on periaatteessa kaksiarvoinen muuttuja (joka saa arvot 'äänestää' tai 'ei äänestä'). Kokonaisäänestysaktiivisuus määritetään kaikkien äänten summana, joten kaikki summamuuttujille kirjattu päättely yllä pätee suoraan. Korrelaatiot ovat myös pienemmät kuin tarkasteltaessa puoluekohtaisia kannatuksia johtuen mm. suuremmasta summan jäsenten lukumäärästä ja siitä että puoluevalintaan kohdistuu monenlaisia vuorovaikutustekijöitä.
Tarkastellaan seuraavaksi puoluekohtaisia kannatusjakaumia. Rehellisissä vaaleissa puoluekohtaisen kannatuksen todennäköisyystiheys K:lle puolueelle mallinetaan multinomijakaumana
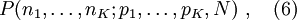
jossa 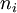 on puoluetta i äänestäneiden määrä,
on puoluetta i äänestäneiden määrä, 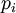 on puolueen i keskimääräinen kannatustodennäköisyys ja
on puolueen i keskimääräinen kannatustodennäköisyys ja 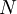 on äänestäjien kokonaislukumäärä. Yksinkertaisuuden vuoksi oletamme ensin että äänestäjät ovat toisistaan riippumattomia, jolloin yhtälö pätee pienemmillekin äänestäjämäärille. Kun kasvaa suureksi ja todennäköisyydet eivät lähesty nollaa, jakautuma (6) lähestyy uusien muuttujien
on äänestäjien kokonaislukumäärä. Yksinkertaisuuden vuoksi oletamme ensin että äänestäjät ovat toisistaan riippumattomia, jolloin yhtälö pätee pienemmillekin äänestäjämäärille. Kun kasvaa suureksi ja todennäköisyydet eivät lähesty nollaa, jakautuma (6) lähestyy uusien muuttujien
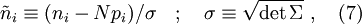
(missä 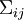 on kovarianssimatriisi) normaalijakaumaa [4]. Ilman affiinimuunnosta saadaan gaussinen jakauma jossa singulaarinen kovarianssi (7) [5]. Kun
on kovarianssimatriisi) normaalijakaumaa [4]. Ilman affiinimuunnosta saadaan gaussinen jakauma jossa singulaarinen kovarianssi (7) [5]. Kun 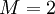 voidaan tämä tulos johtaa tarkastelemalla satulapistelaajennusta keskiarvon ympärillä kuten lähteessä [6]. Jos äänestäjät eivät ole toisistaan riippumattomia, voimme taas olettaa että käytettäessä sopivia summamuuttujia (0) yhdessä klusteroituvuusoletuksen kanssa, ovat summamuuttujat
voidaan tämä tulos johtaa tarkastelemalla satulapistelaajennusta keskiarvon ympärillä kuten lähteessä [6]. Jos äänestäjät eivät ole toisistaan riippumattomia, voimme taas olettaa että käytettäessä sopivia summamuuttujia (0) yhdessä klusteroituvuusoletuksen kanssa, ovat summamuuttujat
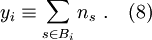
toisistaan riippumattomia, kun summaaan on sisällytetty keskenään korreloituneet satunnaismuuttujat. Jatkamalla summamuuttujien summausta päästään skaalaan jossa summamuuttujien summat ovat gaussisesti jakatuneita. Tämä voidaan edelleen ilmaista yhtälön (8) avulla yksinkertaisesti tekemällä osajoukot 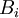 riittävän laajoiksi (esim. vaalipiirin kokoisiksi mutta pienemmiksi kuin esim. hallintoalueen koko.) Tällöin pätee
riittävän laajoiksi (esim. vaalipiirin kokoisiksi mutta pienemmiksi kuin esim. hallintoalueen koko.) Tällöin pätee
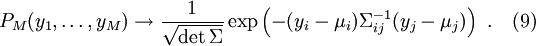
Kaava (9) pätee siis riippumattomille muuttujille, joita voivat olla summamuuttujat 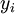 tai 'mikroskooppiset' riippumattomat muuttujat , jotka noudattavat esim. multinomijakaumaa (6). Jälkimmäisessä tapauksessa
tai 'mikroskooppiset' riippumattomat muuttujat , jotka noudattavat esim. multinomijakaumaa (6). Jälkimmäisessä tapauksessa 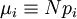 rajalla
rajalla 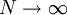 ja ei-infinitesimaalinen.
ja ei-infinitesimaalinen.
Indeksijoukko voidaan jakaa osiin mielivaltaisen monilla tavoilla. Yksi mahdollinen jako on erotella eri äänestyskäyttäytymiseen vaikuttavat selittäjät omiksi dimensioikseen. Tällaisia voivat olla esim. maantieteellinen paikka (useita eri resoluutiota vaikka kylätasolle asti riippuen korrelaatioiden kantamasta) 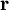 , tuloluokka
, tuloluokka 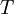 jne. Siis
jne. Siis ![i = [\mathbf{r}, T, \ldots]](/fi-opwiki/images/math/9/4/8/94818384c8bfb02833c5e8df87dded2b.png) . Voimme siis kirjoittaa yhtälön (9) uudelleen:
. Voimme siis kirjoittaa yhtälön (9) uudelleen:
![P[y(\mathbf{r}, T, \ldots)] \to \frac{1}{\sqrt{\det\Sigma}} \prod_{\mathbf{r}, T} \prod_{\mathbf{r}', T'} \exp\left(-(y(\mathbf{r}, T) - \mu(\mathbf{r}, T)) \Sigma^{-1}(\mathbf{r}, T; \mathbf{r}', T') (y(\mathbf{r}', T') - \mu(\mathbf{r}', T')) \right)\ .\ \ \ (10)](/fi-opwiki/images/math/e/c/a/eca55637a8dc1f9a35dc85c34e63f505.png)
Kaavat (9) ja (10) pätevät modulo normalisaatio
![\int\!\! {\mathcal D}y(\mathbf{r}, T, \ldots)\, P[y(\mathbf{r}, T, \ldots)] = 1\ .](/fi-opwiki/images/math/7/e/2/7e20889c40993e723f89e79a63d1432f.png) .
.
Mikäli jakautuma (10) on syntynyt esim. multinomiaaliprosessista rajalla , jolloin 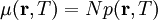 voidaan maantieteellinen indeksi liittää esim. jokaiseen vaalipiiriin (tällöin sillä on siis diskreetti määrittelyjoukko). Olettamalla vaalipiirit toisistaan riippumattomiksi saadaan täysin faktorisoituva jakauma (10). Myös korrelaatioita voidaan vaalipiirien välillä karkeimmillaan mallintaa olettamalla kovarianssimatriisi
voidaan maantieteellinen indeksi liittää esim. jokaiseen vaalipiiriin (tällöin sillä on siis diskreetti määrittelyjoukko). Olettamalla vaalipiirit toisistaan riippumattomiksi saadaan täysin faktorisoituva jakauma (10). Myös korrelaatioita voidaan vaalipiirien välillä karkeimmillaan mallintaa olettamalla kovarianssimatriisi 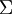 sellaiseksi että odotusarvot
sellaiseksi että odotusarvot 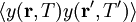 (laskettuna yli jakauman (10)) eivät faktoroidu vaan säilyttävät sellaisen korrelaation asteen, jota vaalidatasetti tukee. Mikäli korrelaatiot ovat voimakkaita, ei oletus jakauman (10) gaussisesta muodosta ole enää välttämättä järkevä ja vaihtoehtoisia muotoja on testattava.
(laskettuna yli jakauman (10)) eivät faktoroidu vaan säilyttävät sellaisen korrelaation asteen, jota vaalidatasetti tukee. Mikäli korrelaatiot ovat voimakkaita, ei oletus jakauman (10) gaussisesta muodosta ole enää välttämättä järkevä ja vaihtoehtoisia muotoja on testattava.
Tuntemattomien selittäjien (piilomuuttujien) olemassaolon vaikutukset (esim. korrelaatiota lisäävät puoluesidonnaisuudet, vaalivilppi tms.) voidaan riittävän heikkojen korrelaatioiden tapauksessa minimoida tai jopa eliminoida summaamalla 'ylimääräisten' muuttujien yli. Esim. summaamalla tuloluokan yli saadaan muuttuja
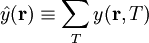
joka summamuuttujana voi olla huomatavasti gaussisemmin jakautunut kuin 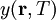 (ts. summaamalla yli tuloluokan tai puoluesidonnaisuuden saadaan kaikkien samaan vaalipiiriin kuuluvien eri tuloluokkia tai puolueita edustustavien äänestäjien vaikutus 'keskiarvostettua pois'). Jos siis
(ts. summaamalla yli tuloluokan tai puoluesidonnaisuuden saadaan kaikkien samaan vaalipiiriin kuuluvien eri tuloluokkia tai puolueita edustustavien äänestäjien vaikutus 'keskiarvostettua pois'). Jos siis
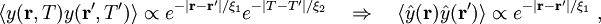
missä mahdollisesti 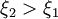 (anisotrooppisessa korrelaatiossa piilomuuttujan korrelaatiopituus on suurempi). Summauksen (piilomuuttujakeskiarvostuksen) jälkeen ainoastaan maantieteellisellä korrelaatiopituudella
(anisotrooppisessa korrelaatiossa piilomuuttujan korrelaatiopituus on suurempi). Summauksen (piilomuuttujakeskiarvostuksen) jälkeen ainoastaan maantieteellisellä korrelaatiopituudella 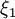 on merkitystä. Keskiarvostusargumentti tukee jakautuman muuttumista gaussisempaan suuntaan monijäsenisille summamuuttujille vaikka emme edes pysty tunnistamaan kaikkia
on merkitystä. Keskiarvostusargumentti tukee jakautuman muuttumista gaussisempaan suuntaan monijäsenisille summamuuttujille vaikka emme edes pysty tunnistamaan kaikkia 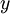 :n argumentteina olevia (piilo)muuttujia.
:n argumentteina olevia (piilo)muuttujia.
Maantieteellisessä mielessä pitkänkantaman korrelaatiota voi syntyä esim. puoluesidonnaisuuksista vaikka oletusarvoisesti myös puoluekohtaiset jakautumat ovat likimain gaussisia. Voimaakkaasti ei-gaussinen anomalia, erityisesti suurten kannatusprosenttiosuuksien kohdalla, voi olla myös signaali vaalivilpistä.
Jakautuma pienillä ja suurillä äänestysprosenteilla
Lopuksi voimme todeta, että pyrkimällä suurempiin yksiköihin äänestyskäyttäytymisen tarkastelussa (esim. vaalipiiritasolta hallintoalue/tasavaltatasolle) pitäisi summamuuttujien tulla aina tarkemmin gaussisiksi satunnaismuuttujiksi. Koska pienillä äänestäjämäärillä summamuuttujat sisältävät vähemmän summattavia, eivät korrelaatiot tule välttämättä eliminoiduiksi kovin tehokkasta, ja tästä syystä sekä kokokonaisäänestysaktiivisuuden että puoluekohtaisten kannatusjakaumien käyttäytyminen pienillä äänestysprosenteilla voivat poiketa huomattavasti Bellin käyrän muodosta. Tämä ilmiö onkin näkyvissä monien jakautumien kaksoispiikkirakenteena se. toinen piikki on ilmenee pienillä äänestysprosenteilla lähellä nollaa. Sama poikkeaman mahdollisuus pätee tietysti myös suurilla prosenttiosuuksilla jos vaalipiiri on kooltaan hyvin pieni. Tällaiset vaalipiirit voidaan kuitenkin helposti eliminoida statistiikasta ja voimme olettaa että suurilla prosenttiosuuksilla jakautumien pitäisi käyttäytyä tarkemmin normaalikautuman mukaisesti kuin pienillä.
Huomioita
- Berry–Esséen theorem
- korreloimattomuus ei implikoi riippumattomuutta mutta päinvastainen pitää paikkansa .
- Jo muutama konvoluutio riittää tuottamaan likimain Bellin käyrän muodon jopa vahvasti ei-gaussiselle muuttujalle [1]
- marginal distriubution (how to construct joint probability distributions with hidden variables using conditional probabilities and chain rule of probability [7].))
- Multinomial distribution (continuous analogue is multivariate normal distribution) [4]
- Election fraud investigation in US electronic polling (partywise data comparison and Gaussian distribution of support) [8]
- Gaussianity of support in Malaysia 2008 compared with Singapore 2006 showing that even in a fair election the won seats a 50%-50% result split between opposition and governing parties may result in a massively non-balanced distribution of seats in the parliament [9]
- Skewness [10] (actual numbers and the skewness of the distribution demonstrated)
- Marginal distribution (hidden var.) [11]
- Basic statistical inference (parameter estimation for fitting distributions to a single realization of a random process [12])
- Marginal distribution of the multinomial distribution [13]
Katso myös
- Arvioinnin pääsivu: Venäjän_vaalit_2011
Viitteet
- ↑ 1,0 1,1 Wikipedia: | Multivariate_central_limit_theorem
- ↑ Brazilian Journal of Physics 39 (2009) 371
- ↑ Wikipedia: Lyapunov's theorem CLT (non-identically distributed random variables)
- ↑ 4,0 4,1 Wikipedia: | Multinomial distribution
- ↑ Confidence region for the multinomial parameter with small sample size (D. Chafai, D. Concordet, preprint 2008, p. 3)
- ↑ MathWorld: Binomial distribution
- ↑ Wikipedia: Joint_probability_distribution
- ↑ Election fraud investigation US (p.14)
- ↑ The Mathematics of Elections (Singapore Democrats)
- ↑ The Mathematics of Elections 2
- ↑ Wikipedia: | Marginal distribution
- ↑ Topics in statistical methodology (S. Biswas)p. 329 - 337
- ↑ AI Access
